什么是 Kafka
Kafka 是一个开源的分布式事件流式消息平台, 它通过一系列的机制实现了高吞吐, 因此常见于大数据的处理. 并且在后续更新中增加了高可用的特性, 使得它可以被更广泛的用于数据分析甚至银行等领域.
回顾历史, Kafka 是应 LinkedIn 处理海量日志的需求而诞生的, 在这种场景下, 日志的重复和丢失并不是什么特别大的问题. 因此, 初期的 Kafka 并不具备高可靠信息传输的能力, 但是由于它极高的高吞吐量, 使得它被大家用在了其它场景下, 而随着用户和需求的增加, Kafka 在后续的版本中也加入了对消息可靠性的处理, 以及事务提交的能力.
是什么构成了 Kafka
在开始之前, 先来看一下常规的 Kafka 架构图:
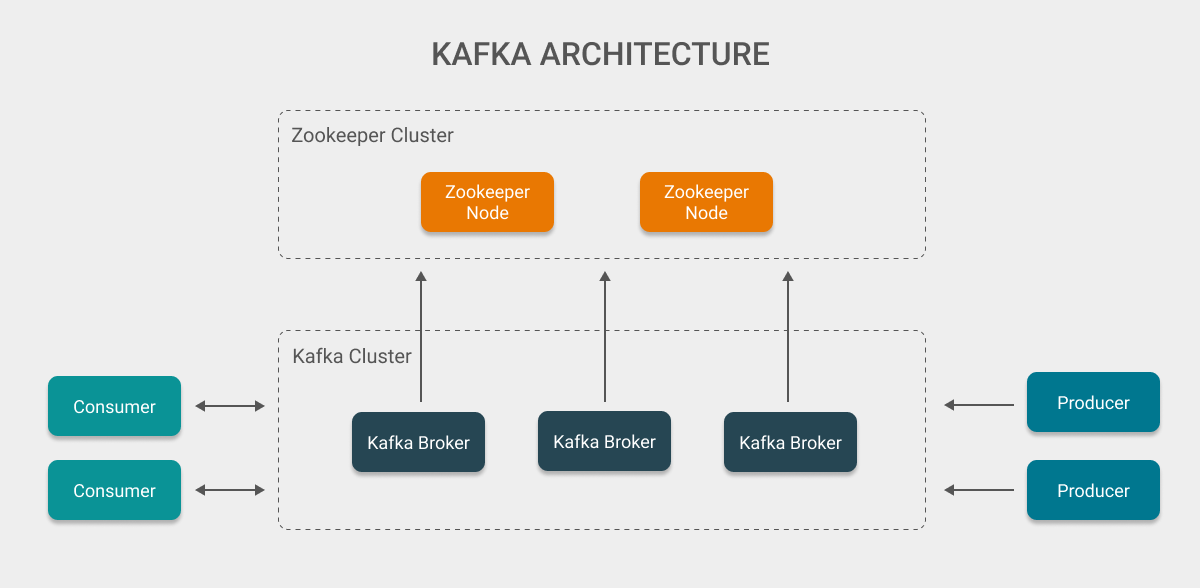
这里的 Kafka Broker 表示一个 Kafka 服务 (当然你也可以称它为 Kafka Server 或 Kafka Node), 而多个 Kafka Broker 共同组成一个 Kafka 集群来对外提供服务. 同时, 这里还有两个角色: Consumer 和 Producer, 一般来讲这两个角色实际上都是由自己编写的服务 (即 Kafka 的使用者).
由名称可以知道 Producer 是向 Kafka 服务发送消息的, 因此它有一个单向箭头用于表示消息的发送. 而 Consumer 除了负责消息的消费以外还负责主动向 Kafka 服务来提交自己消费的偏移量, 同时还有一些消息用于消费者 Leader 的选举, 这些会在稍后的过程中讲到, 当下只要知道有这些东西即可.
图中还有一个重要角色: Zookeeper, 它负责管理 Kafka 集群中的元数据, 并用来进行 Controller (一个具有特殊功能的 Kafka Broker 节点) 选举. 对 Zookeeper 感兴趣的朋友可以去具体了解它能做什么, 不过在这里你可以简单的认为它是一个用于数据存储和通知的分布式服务即可.
Kafka 计划在后续的版本中移除对 Zookeeper 的依赖, 并基于 Raft 协议实现了元数据管理和 Controller 选举用于替换 Zookeeper. 具体内容可以参考: KIP-500
Kafka Topic
同样, 这里使用对应的图片来描述 Kafka Topic:
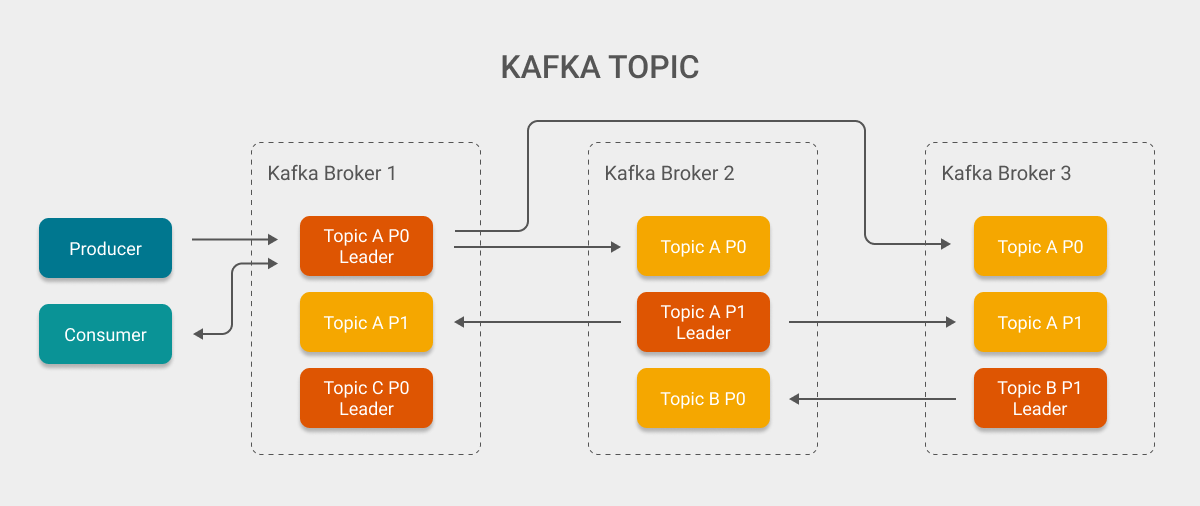
首先需要提到的是 Consumer, Producer 和 Topic. 由于 Kafka 使用的是发布/订阅模型, 因此要使用 Kafka 需要先创建对应的 Topic, 随后使用 Producer 向 Topic 发送消息, 而 Consumer 通过订阅 Topic 来从中接收消息.
为了保证系统的可用性, Kafka 支持在创建 Topic 的时候指定副本因子, 这意味着对应的 Topic 内的数据会被复制到不同的 Broker 中来尽可能的保证不会因为单个 Broker 离线而导致某些 Topic 不可用 (当然, 你可以把副本因子设置为 1 来表示不需要而外的数据冗余).
针对于副本间数据的同步, Kafka 使用了 Leader/Follower 模型, 其中 Leader 负责向 Consumer 和 Producer 提供服务, 而 Follower 只是负责从 Leader 同步数据. 这意味着在正常运行中 Follower 相当于热备份. 当 Leader 离线后, Controller 会及时发现对应的情况, 并依据规则从 Follower 中挑选一个作为新的 Leader. 在该选举行为完成后所有的 Follower 将会从新的 Leader 处同步数据.
这里有一个问题: 如果所有的 Producer 和 Consumer 都只和 Leader 进行交互的话, 很显然 Leader 会很快成为系统的瓶颈.
因此, 为了保证系统的整体性能并避免出现性能瓶颈, Kafka 支持将 Topic 划分为多个 Partition 并且每个 Partition 都有属于自己的 Leader (如果副本因子大于 1 还会有对应的 Follower), Producer 会将消息依据规则发送给 Topic 中 Partition 的 Leader, Consumer 会从 Partition 的 Leader 中消费消息. 同时, Kafka 内部也有机制来保证 Leader 会尽可能被均匀的分配到不同的 Broker 上.
如上图中的 Topic A, 就具有两个 Partition, 分别为 P0 和 P1. 并且 P0 和 P1 的 Leader 分别在不同的 Broker 上, 这里假设消息依据规则被均匀的分配给这两个 Partition, 那么就意味着这两个 Broker 分担了 Topic A 的所有流量.
Kafka Log
假设现在有一个 Topic, 它有三个 Partition 来分担发送到整个 Topic 中的消息. 那么这个 Topic 在 Kafka 中的存储结构大致如下图所示:
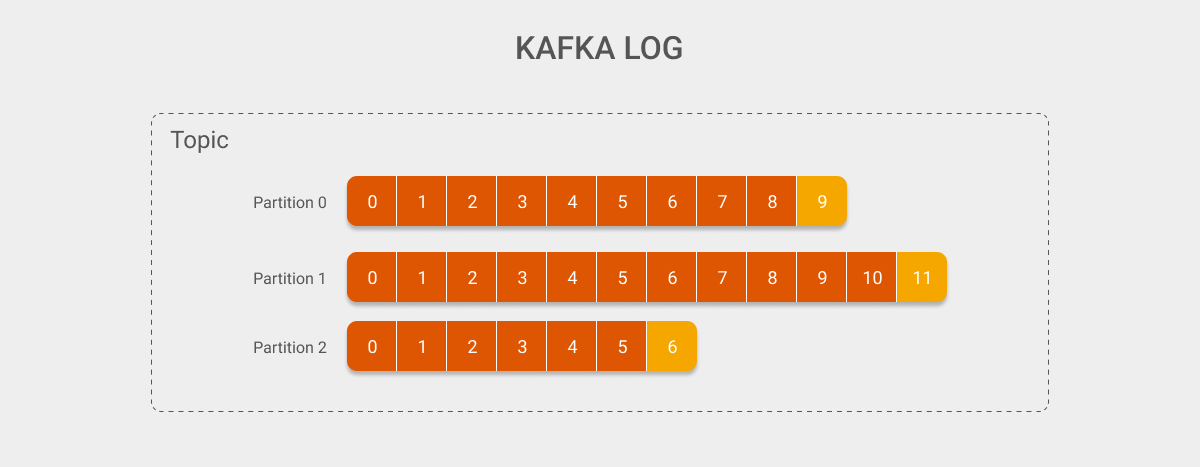
图上橙色的方块表示已经使用了的 Offset, 而黄色方块则表示下一条消息到来时会存储到哪个 Offset.
由于发送给 Kafka 的消息会实际存储到 Log 文件中, 因此这里使用 Kafka Log 来表示实际消息的存储. 可以看到图上有三个 Partition, 其中每条消息在不同 Partition 中都使用 Offset 进行表示. 比如, Partition 0 的第 0 个 Offset 对应的就是 Partition 0 的最早的一条消息. 以及, 虽然不同 Partition 的 Offset 看似有重合, 但实际上它们表示的是完全不同的数据.
同时, 这里可以看到不同的 Partition 之间数据长度也有所不同, 这是因为 Producer 会依据规则将消息发往不同的 Partition:
- 当消息中 Key 有值时, 依据 Key 的哈希来确定对应的 Partition.
- 当消息中 Key 没有值 (为 null) 时, 使用轮询的方式来发往不同的 Partition.
- 如果消息中指定了对应的 Partition, 则直接将消息发往对应的 Partition.
由此也可以看出 Kafka 的生产者其实是一个 “智能” 的客户端, 它代替 Kafka 服务实现了消息分发到不同 Partition 的功能, 同时, Kafka Client 还支持为生产者编写自定义分区器, 可以使消息依据业务需求发往不同的 Partition.
Kafka Replica
这次, 下图假设有一个副本因子为 3 的 Topic, 该 Topic 中 Partition 的 Leader 和 Follower 分别分布在 Broker 0, 1 和 2 上. 其中分配在 Broker 1 上的是 Leader 其余的则是 Follower.
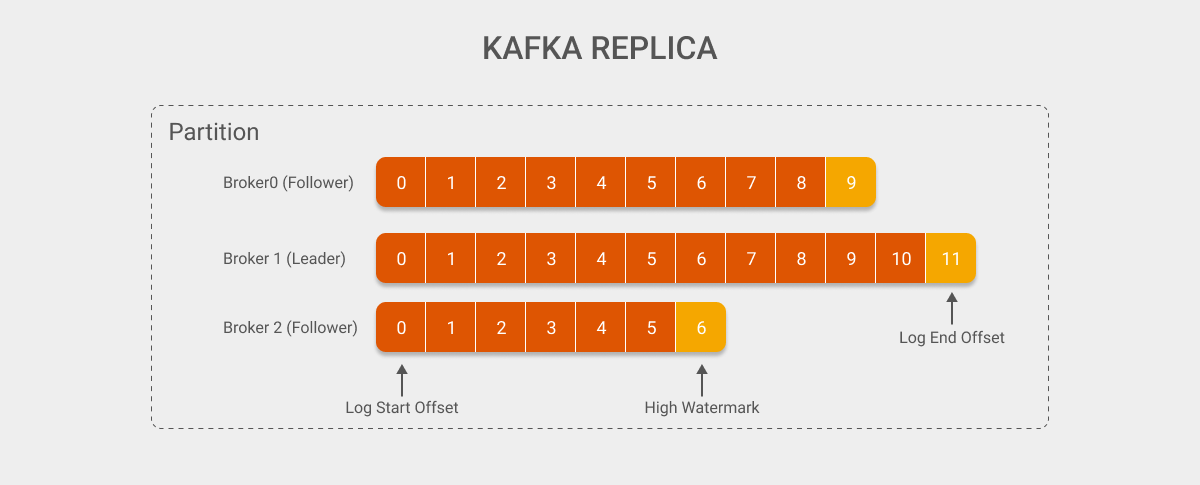
首先, 先来解释一下上图中新出现的概念:
- Log Start Offset: 日志文件中第一条消息对应的 Offset.
- High Watermark: Consumer 可以消费的 Offset + 1 (ISR 中最小的 Log End Offset).
- Log End Offset: 日志文件中最后一条消息的 Offset + 1.
其中的 ISR (In-Sync Replica) 指的是动态的和 Leader “足够” 同步的 Follower 列表, 它决定了 Kafka 服务的可靠性, 同时也间接的影响了 Consumer 所能消费的消息长度.
当发送一条消息到 Kafka Topic 后, 对应的 Partition Leader 会收到这条消息并记录到磁盘上, 随后 Follower 会定时的从 Leader 拉取最新的数据 (Kafka 消息通信使用的是 Pull 模型), 每当 Follower 拉取到对应的消息后 Leader 就会更新对应 Follower 拉取到的最新的 Offset, 当处于 ISR 中的 Follower 都拉取到新的消息后 Leader 便会更新对应的 High Watermark, 随后 Consumer 便可以看到该条消息从而进行消费.
ISR 是 Kafka 中高可用和高并发的一种权衡机制, 在高可用方面, 它决定了什么样的 Follower 才能被选为 Leader 从而可以避免消息的丢失 (具体参考下文的 Kafka Producer). 同时, 当消息同步到所有的 ISR 后 Kafka 便认为该消息已经处于可靠状态, 而非将消息同步到所有的 Follower 中 (理想情况下, 当网络条件良好时, 所有的 Follower 都可能在 ISR 中, 不过这种情况下不存在部分节点因为网络问题拖慢消息的同步, 所以不在考虑范围内) 从而提高了系统的吞吐量.
当集群网络状况较差或者整体负载过大时, ISR 有可能只存在 Leader 一个节点, 这将会导致服务的可用性降低 (默认配置下, 当 Leader 宕机后, 将无法选出新的 Leader), 这个时候可以设置 min.insync.replicas 来限制最小的 ISR 数量, 这可以在牺牲吞吐量的情况下保证系统的可用性.
如果当前运行的服务要求较高的吞吐量并且不在意消息的丢失的话, 可以通过设置 unclean.leader.election.enable 为 true 的方式来提高系统的可用性, 该参数表示: Kafka 将可以从 ISR 列表之外的 Follower 中选取一个作为 Leader. 由于 Kafka 消息的同步是同步到所有 ISR 中就算成功. 因此, 当非 ISR 中的节点被选为 Leader 时可能会导致消息的丢失.
Kafka Controller
Controller 其实是一个特殊的 Kafka Broker 节点, 它用于 Partition Leader 选举, 维护集群的元数据, Topic 管理等.
之所以说 Controller 是一个特殊的 Broker, 是因为它其实是 Broker 通过选举竞选出来的. 当 Broker 竞选 Controller 时, Broker 会尝试在 Zookeeper 集群中创建一个临时的 /controller 节点, 依托于 Zookeeper 的机制, 当多个 Broker 尝试去创建这个临时节点时, 只有一个会成功. 因此, 成功创建节点的 Broker 就会被选为 Controller.
当 Controller 因为某些原因宕机或是由于 Full GC 从而没有及时与 Zookeeper 进行交互, 那么 Broker 和 Zookeeper 之间的 Session 将会过期, 对应的 /controller 也会被删除, 在这种情况下会触发新一轮的选举, 从而保证不会因为 Controller 的故障导致 Kafka 集群不可用.
消息的生产与消费
Kafka Producer
关于 Producer 的职责, 前面的内容中已经简单的描述过了: 它主要负责向指定 Topic 发送消息, 同时依据消息内容 (主要指 Key) 的不同将消息发送至不同的 Partition.
这里还有一个常见且重要的参数: acks, 它决定了 Producer 发出去的消息如何才算发送成功, 该参数有四个可配置的值:
- 0: 该值表示 Producer 将不会等待服务器的返回, 当网络抖动或者服务宕机时, 该消息就会丢失.
- 1: 该值表示 Producer 会等待 Leader 将对应消息保存到本 Log 文件中, 但是不会等待足够 Follower 同步到这条消息, 当 Leader 在收到消息并返回给 Producer 之后突然宕机, 该消息就会丢失 (因为被选为新 Leader 的 Follower 并未同步到这条消息).
- all: 该值表示 Producer 会等待 Leader 将消息保存到 Log 文件中, 且等 ISR 集合中的 Follower 都同步到该消息后才会返回, 在这种情况下, 只要有足够的 ISR 那么消息就不会丢失.
- -1: 该值的含义等同于 all.
在实际使用的过程中, 如果将 acks 配置为 all, 一般需要进一步的配置 min.insync.replicas 来防止消息的丢失.
Kafka Consumer
Consumer 经常以 Consumer Group 的形式出现. 一个 Consumer Group 中可能会包含多个 Consumer, 这些 Consumer 分别消费 Topic 中不同的 Partition 的数据, 具体结构如下图:
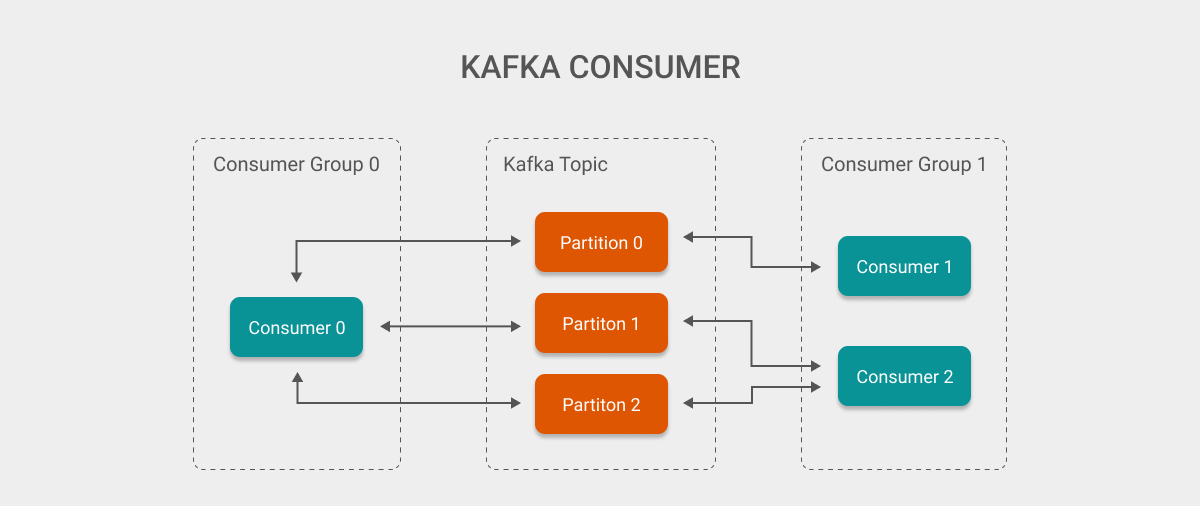
Kafka 可以通过创建多个 Consumer Group 来实现发布/订阅模型, 这意味着不同 Consumer Group 之间的消费进度是完全独立的. 在此之上, 同一个 Group 中的 Consumer 会分配到不同的 Partition 来共同消费同一个 Topic 的消息,
当 Consumer Group 中 Consumer 的数量小于 Topic 中 Partition 的数量时, 部分 Consumer 可能会分配到多于一个的 Partition, 如图中, Consumer 0 分配到了三个 Partition, 而 Consumer 2 分配到了两个. 这时, 可以通过增加 Consumer 的数量至 Partition 的数量来提高系统消息的消费速度.
但是, 当 Consumer Group 中 Consumer 的数量大于 Topic 中 Partition 的数量时, 会存在部分 Consumer 可能没有分配到任何 Partition 的情况 (为了避免消息的重复消费). 因此, 在这种情况下多出来的 Consumer 实际上不会消费任何消息.
因此, 合理的设置 Partition 和 Consumer 的数量是提高系统吞吐量相当重要的一环.
至此, 结合 Producer 的发送逻辑, Consumer 的消费逻辑以及 Log 的具体结构, 可以看出 Kafka 的消息在 Partition 级别是有序的, 而在 Topic 级别是无序的.
这是因为 Producer 会顺序的将消息发送至不同的 Partition, Partition 则会依据消息到来的顺序进行存储, 而 Consumer 则会顺序的对 Partition 中的数据进行消费, 因此可以说消息在 Partition 级别是有序的. 而站在 Topic 的视角上, 由于可能会有多个 Consumer 来消费不同 Partition 中的消息, 这时是无法保证消息在 Topic 级别被顺序消费的.
总结
至此, 本文介绍了 Kafka 中常见的基础概念, 其中包括了 Topic, Replica 和消息的生产与消费等, 在阅读完本文后, 相信你应该对 Kafka 有了进一步的了解 (如果你之前只是听说过 Kafka 的话).
不过, 还有很多内容并没有在本文中详细描述, 例如: Leader 选举 (Partition Leader 和 Consumer Leader), Controller 的具体职责, Kafka Log 具体的存储方式等, 这些会在后续的文章中详细描述.