引子
之前毕业的时候尝试使用 C++ 写过一个即时通讯服务, 当时参考了蘑菇街开源的 TeamTalk, 同时为了学习/练手没有使用太多的外部依赖库. 时隔多年, 现在计划把当出学到的东西简单沉淀并记录一下, 也有助于后续的回顾和提升.
关于网络, 在微服务概念盛行的当下贯穿着整个系统, 毕竟服务总需要通过网络来相互交互并向最终用户提供服务, 因此了解对应的知识也有助于提升对整体系统和交互流程的理解.
阻塞与非阻塞IO
在这里我们会了解关于阻塞与非阻塞的概念, 不过在开始之前我们先来了解一下 Linux 的网络栈:
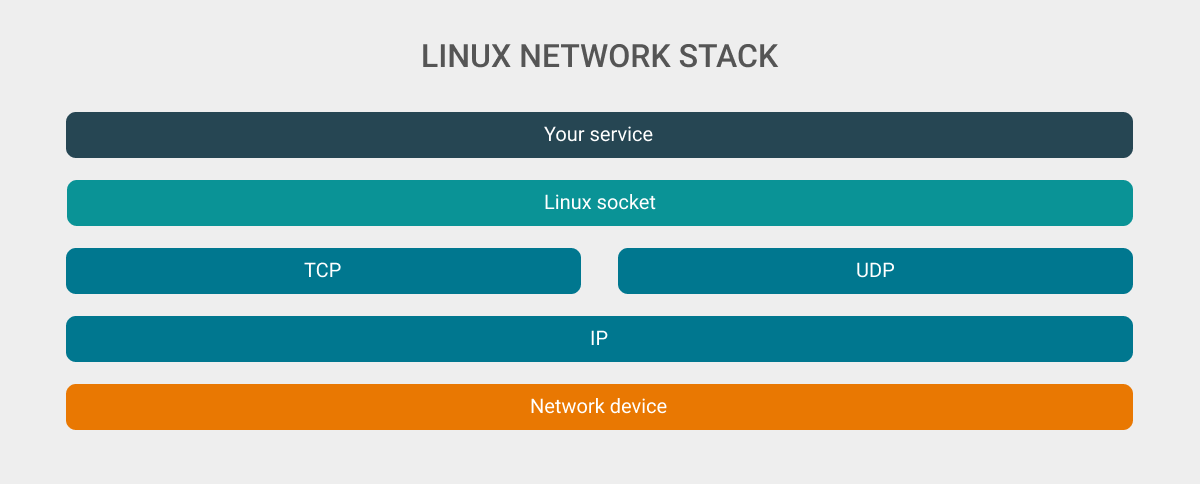
这是一个极度抽象化后的 Linux 网络栈, 我们程序的数据通过 Linux socket 进行操作, 其中依据创建时的不同类型 (即: TCP, UDP 或其他协议) 在 Linux 网络内核中会有不同的操作, 最终封装为 IP 数据包并通过驱动层发送给网络设备最终到达接收端.
在 Linux 初始化 socket 的时候会创建缓冲队列用于发送/接受消息, 同时缓冲队列是有长度限制的, 因此当我们尝试发送数据但是缓冲队列已满或者尝试接收数据但是缓冲对列为空时程序的处理便会遇到问题.
在了解上述的基础知识后, 我们可以进一步了解什么是阻塞与非阻塞 IO:
阻塞 IO
默认情况下 Linux 会阻塞当前程序直到缓冲对列可以将所有需要发送的数据放入队列为止. 因此默认情况下创建的 socket 对其进行的操作都算是阻塞 IO.
在一般情况下, 尤其是对网络客户端来说,阻塞 IO 其实并没有什么大的问题, 因为往往客户端需要建立的连接数较少. 同时阻塞 IO 会等待数据发送/接受完成才会返回执行, 因此不需要考虑过多的情况, 只需要依据业务需求进行下一步处理即可.
但是阻塞 IO 对服务端尤其是高并发的服务来讲就会造成问题, 因为阻塞 IO 会受限于缓冲区数据的有无从而可能会阻塞住当前线程, 这对于高并发的服务来讲是难以接受的, 我们可以简单的为每次网络请求创建一个线程进行对应操作, 但是线程的上下文切换会导致系统的整体性能下降. 使用线程池的话又会遇到所有线程都被阻塞导致后续任务延迟执行的问题.
非阻塞 IO
基于阻塞 IO 的特点, 我们再来看一下非阻塞 IO. 就如同字面含义, 进行网络操作时无论缓冲区数据是否可以满足当前操作, 非阻塞 IO 都会立即返回同时告知调用方发送/接受了多少字节的数据, 随后程序可以依据数据发送/接受了多少来决定下一步该如何处理.
相较于阻塞 IO, 非阻塞 IO 由于立即返回的特性更适合在高并发系统中使用, 但是随之而来的问题是它会增加程序编写的复杂度.
设想一下, 我们需要给客户端发送数据, 但是由于发送缓冲区不足以放下所有数据, 因此我们的程序需要考虑将未发送的数据缓存起来, 在之后时机合适的时候进行发送, 尤其是有多次连续的发送请求, 在极端情况下需要对所有请求数据进行缓存, 从而导致内存占用过高.
如何进行选择
如上所述, 当我们在没有高并发需求, 同时需要编写更简单代码的情况下阻塞 IO 是一个不错的选择, 尤其是在等待操作完成后才会返回的特性更加符合顺序操作的思考逻辑.
而对于高并发程序来讲非阻塞 IO 则更加适合, 同时非阻塞 IO 往往会和事件循环或者异步事件通知结合使用, 从而在缓冲区可以进行对应操作时及时的得到通知并进行相关的操作, 但是对于其缓存未发送的数据问题, 则需要使用者依据具体的业务进行权衡.
事件循环与异步事件通知
在 Linux 网络编程中, 对于网络相关的操作对应着多种事件, 其中常见的有: 新连接建立, 有数据可读, 数据可写和连接断开这四种事件.
其中我们将读/写事件与非阻塞 IO 结合起来后便很容易编写出具有高并发特性的代码, 首先相关的操作不会阻塞住程序的执行, 其次程序也可以在合适的时机获知到可进行的操作从而执行相关的发送或接受的逻辑, 进一步的提升了服务器资源的利用效率.
事件循环
事件循环是一种编写高并发程序的方式, 它的核心是利用操作系统的 API 来实现 IO 多路复用 (即, 使用单个线程来监听多个 IO 的状态), 并在 IO 状态满足对应事件的时候触发相应的逻辑.
如果将事件循环, IO 多路复用, 非阻塞 IO 以及线程池结合起来就可以实现常见的 reactor 模型:
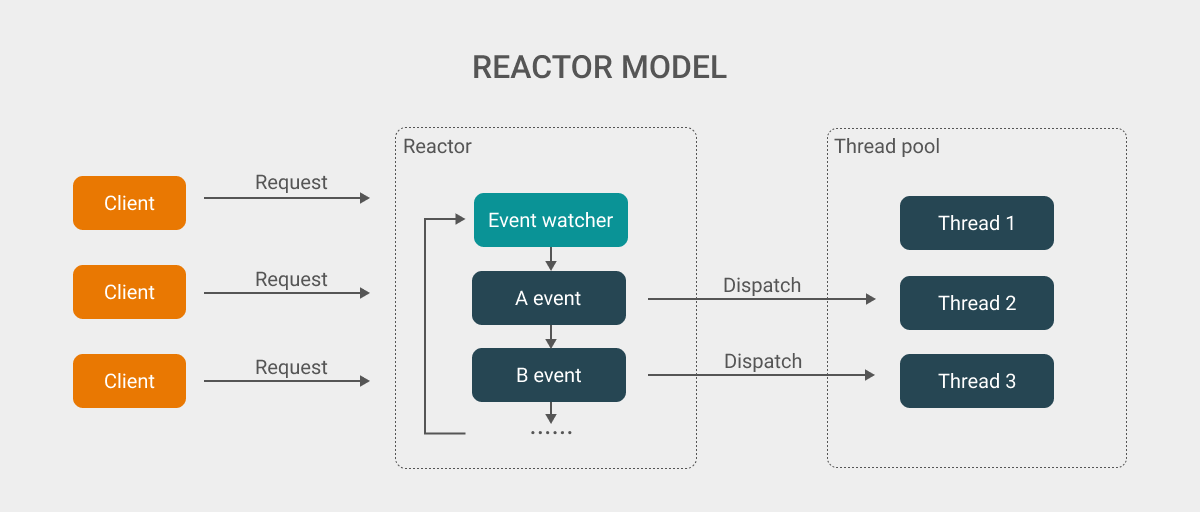
由于是自己手画 (画图技术不熟练), 所以上图也是一个简化后的 reactor 模型, 其中客户端发送的请求 (包括请求建立连接, 发送数据等)都会触发对应的事件, 而在 reactor 顶部的 event watcher 会同时在阻塞状态下监听多个连接的状态, 当监听的连接中有对应的事件发生后, event watcher 的阻塞状态便会被解除.
随后, 我们在程序中依据触发的不同的事件来决定需要对连接进行什么操作 (读取, 写入和关闭等), 在通常情况下执行的代码不会放入 event watcher 解除阻塞后的代码段中. 这是因为: 如果遇到较为耗时的操作时, 该操作将会阻塞其他事件的处理, 从而影响整体系统的响应速度.
对于执行事件任务, 我们一般会引入线程池来解决对应的问题. 因此, 在判断完触发的事件类型之后, 程序便会将对应的数据和任务派发给线程池执行, 程序自身则会继续处理下一个事件, 直至当前所有的事件都处理完毕.
而在事件都处理完毕后, 程序又会回到 event watcher 中继续等待下一次事件的发生 (除非程序已经关闭), 而这个基于事件触发的循环处理的过程又被称为事件循环.
异步事件通知
在开始前, 我们再简单回顾一下上一小节的事件循环, 你会发现它是一个同步的事件发生的过程. 即: 我们知道事件发生了, 然后决定要如何处理, 再然后将任务交由线程池去执行. 这个过程中除了将任务交由线程池去执行以外, 剩下的步骤都是顺序且同步进行的.
现在, 我们再来看一下异步事件指的是什么:
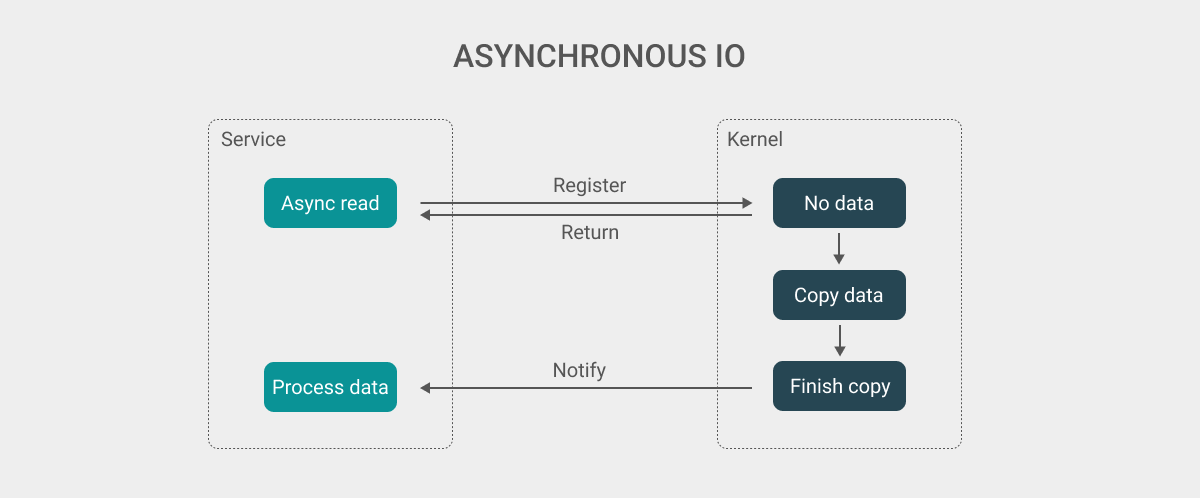
这里我们使用了异步读取数据的例子, 首先我们的服务使用系统的异步读取接口注册了读事件对应的处理方法, 在该方法中我们将会指定一个缓冲区用于存放数据. 依据上图我们可以看到: 在我们注册事件的时候系统暂时无数据可读, 并且此程序也只关注在读取事件的注册上面 (即: 是否注册成功).
随后, 我们假设有数据到来了, 这个时候操作系统会将接收到的数据由内核缓冲区拷贝到我们指定的缓冲区中 (注册事件时所指定的缓冲区), 在完成拷贝之后内核会通知到对应的方法 (通过发送信号或回调函数).
最终, 对应的处理方法被成功调用, 数据也被处理完成, 整个读取操作到这里也就结束了.
回顾这个流程, 你会法下它和上面同步的使用非阻塞 IO 读取最大的不同就是: 读取数据的操作实际上是交由内核完成的, 并且会在完成之后通过某种方法来告知到程序, 而并非先判断是否有对应事件发生, 随后再主动读取.
异步 IO 的出现进一步的帮助我们将视线从数据的具体操作上挪开, 从而关注与数据的处理, 但是同时它也带来了程序难以调试的缺点. 因为我们不知道我们注册的事件什么时候会被执行, 并且对于数据处理部分的代码是脱离于代码主体流程, 这会使得代码更难被理解.
既然讲到了这里, 我们就一起再来看一下 proactor 模型:
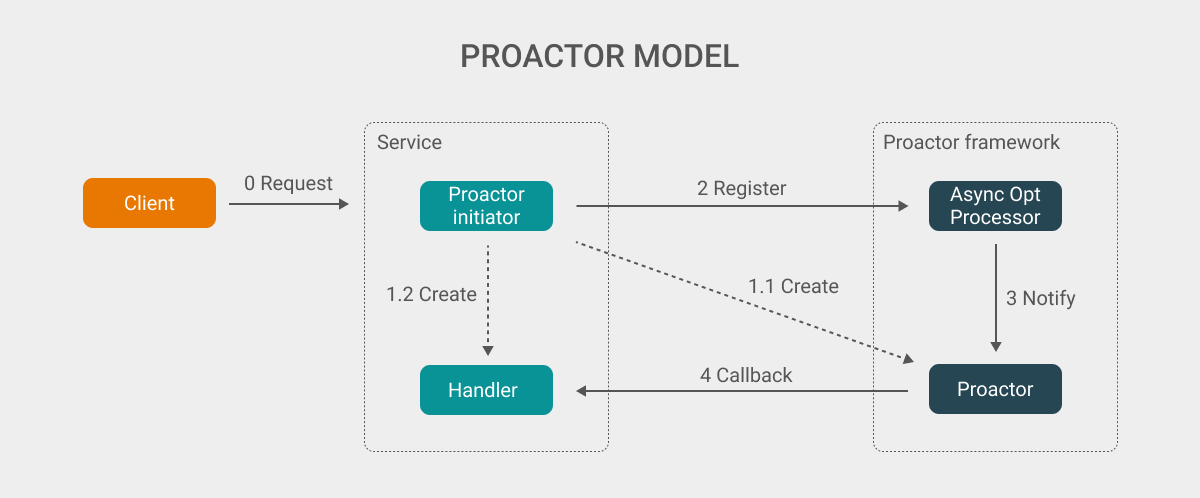
上图是一个简化的 proactor 模型, 当用户请求触发到服务后, 服务会依据具体的业务情况创建出对应的 handler 和 proactor 对象. 其中 handler 包含了对应的数据处理逻辑, 而 proactor 对象则关联了对应的 handler.
在创建完相关的对象后, initiator 会将 proactor 注册到 async operation processor 中, 其中包含了关注的事件 (例如读数据或写数据), 而在对应的事件满足并且数据已经被发送或接受之后, proactor 会通知到对应的 proactor 对象, 在这时 proactor 会依据具体的事件来选择调用不同的 handler (当然也可以对不同的事件创建不同的 proactor 对象).
最终, handler 执行对应的逻辑, 数据处理结束. 其中需要注意的是, handler 也有可能会视情况来创建新的 proactor, 由于上图主要想描述一个简单的流程, 因此并为在图中体现.
关于 proactor 这一段, 我参考了网络上的部分解释, 最终呈现出来的图片是参考知乎回答1来绘制的, 不过其中一些困惑的地方: 在我的理解下 proactor 更接近一种网络的编程模型, 若想简易的实现它就需要依赖于内核所提供的异步 IO 接口, 但是这并不意味着当我们没有异步 IO 接口的时候无法使用 proactor 模式 (例如: 可以通过 reactor 模式来模拟出 proactor 模式的行为, 而作为编程模式模式或者说是框架, 用户无需过多的深究内部实现的细节). 那么这就意味着 Async operation processor 和 proactor 不一定处于内核线程中. 因此, 在上图中我使用了 Proactor framework 来表示该职责/对象是属于 Proactor 的一部分.